Many-Eyes is a site for massively collaborative visual data analysis, allowing users to upload data sets, visualize them, and discuss them online. In this sense, it is similar to other projects like Swivel and Data360, but supports a much broader range of data types and engaging visualizations. And it's a lot of fun to play with!
I had the privilege of working this past summer at IBM Research Cambridge in the Visual Communication group with Martin Wattenberg and Fernanda Viégas. Having watched them and the rest of the team prepare this project, it's exhilarating to see it launched! We also spent time researching and testing additional features to support social data analysis. Look for our upcoming CHI2007 paper (link soon) for more!
A short interview about my experiences and thoughts on information visualization was recently posted on the blog mentegrafica. The text of the mini-interview is included in the extended entry.
1 - When, how and why have you decided to research on infovis ?
As an undergraduate student at Berkeley, I was interested in studying both computer science and psychology, which led naturally to questions of how the design of computer applications could better take advantage of human capabilities. This got me excited about pursuing research in Human-Computer Interaction. I was lucky enough to get an internship at Xerox PARC, working with luminaries like Stuart Card, Jock Mackinlay, and Ed Chi, who introduced me to information visualization as a research field of its own. After graduating from Berkeley, I went back to PARC to work for a year before starting graduate school. It was then that I really started working on infovis projects in depth.
2 - Which is, to you, the most interesting project you have worked on and why ?
Its hard to say, since each subsequent project builds off the lessons learned in the past, so they are all part of a continuous stream of exploration. That said, the most rewarding aspect has probably been the release of prefuse, a visualization software toolkit we developed. Seeing how people have taken the tools, extended them, and built their own visualizations has been wonderful to see, and often inspiring. Its nice to feel that youve contributed something people find useful.
3 - On what themes are you working now ?
Im interested in a wide variety of visualization-related problems, including infovis software tools and automatic optimization of displays according to perceptual principles. However, the theme Im currently most excited about is exploring the social dimension of visualization use how can visualizations be effectively used by groups of collaborators? how can communication mechanisms be effectively introduced to improve analysis? For example, if I put a visualization on the web and thousands of people interact with it, what are the ways in which they can easily communicate their findings and contribute to our greater understanding?
4 - If you should suggest an education programme to a student interested in InfoVis, which University Course do you suggest him/her ?
There are a number of courses that would be useful. A background in computer science and perceptual psychology is indispensable. Courses in computer graphics and human computer interaction / user interface design are very useful, and if available, Id recommend a dedicated course in visualization. For example, Ive been involved in teaching two classes at Berkeley, one in the School of Information and another in the Computer Science department.
I think the field would greatly benefit from more researchers who also have a background in art and design, so classes in graphic design, film, art history, and art practice are also relevant. Ive also found a grounding in the basics of linguistics and semiotics to be quite useful.
5 - How do you think infovis researches will evolve in your country for next years ?
I think infovis research will continue to flourish. I expect there to be continued progress in existing research areas, such as the design of more perceptually effective information displays, across numerous display types (monitors, large displays, cell phones, etc). I also hope more efforts in the collaborative use of visualization and studies of visualization as a communication mechanism arise. Im also optimistic that good design principles and aesthetics will continue to get more attention within the field.
Looking outside of research, widely-accessible, interactive technologies such as Flash and AJAX are increasingly popular, but currently lack support for better data handling and assisting perceptually effective visual mappings. I hope that the set of tools available for creating visualizations will improve, allowing more non-researchers and non-professionals to start creating and exchanging visualizations, while making visualizations more accessible to everyday users. If visualization is released into the wild in this fashion, I expect the rest of us will have a lot to learn from the results.
"Do Europeans feel sad more often than Americans? Do women feel fat more often than men? Does rainy weather affect how we feel?"
The net-art project We Feel Fine attempts to answer some of these questions through a set of playful yet ambitious visualizations backed by data scraped from thousands of blogs.
For those of a more dichotomous temperament, the same data stream is used to power Lovelines, an interactive exploration of statements of love, hate, and everything in between.
The projects were created by my friend Sep Kamvar and his collaborator Jonathan Harris (also responsible for the Webby-winning 10x10 and WordCount visualizations). Should you have any related ideas of your own, the two have made the results of their continual blog-crawling available to all in the form of a public web API.
The Vizster social network visualization by danah boyd and I was used on the CBS crime drama Numb3rs! In the March 3 episode "Protest", the software was used to help illustrate the concept of social networks. Check out the clip:
Using multiple monitors on your desktop is great, and studies have shown it works especially well when different tasks/tools break up cleanly amongst the different screens (e.g., excel and e-mail, coding and documentation). It doesn't quite work as well when trying to expand a single window over all the monitors, because the seams between monitors chop up the space and introduce discontinuities.
This brief ZDNet article mentions some of the wonderful large display work at microsoft research, but the article of course neglects to mention the issue of seams. With multiple monitors, lines/curves become discontinuous, and what should be single elements get chopped up into pieces. This wreaks a bit of havoc with gestalt perception and in my opinion decreases the aesthetic experience of the interface.
What are the solutions? Large displays without seams is one (and microsoft and others are already working on this). For today's consumers, a reasonable stop-gap may be to make interfaces seam-aware, allowing layout and presentation of interfaces to take seams into account (e.g., excel spreadsheet cells could automatically realign to improve readability across monitors). Jock Mackinlay and I devised one approach to building seam-awareness into interfaces, though things being what they are, I don't expect to see it on desktops anytime soon :)
Our second design iteration (v2::grey, with temporal filtering and search) was just presented last week at a great e-mail visualization workshop hosted at the University of Maryland by Ben Shneiderman, Adam Perer, and Douglas Oard. Check it out...
Here's a first pass at some large-scale social network visualization. The layout needs some work, and there's plenty more attributes to explore, etc, etc, but I figured these images might be interesting enough to share now...
Wow, it has been ages since I've posted anything. Please allow me to crawl out from under my rock to announce that I have finished my master's degree. Those with a geek-streak, an interest in turning data into pictures, or are generally masochistic can check out the report.
Sincere thanks to everyone who helped out along the way. You know who you are.
This past Friday I had the pleasure of attending StreetTalk, a one-day workshop on urban-centered computing organized by Eric Paulos of Intel Research Berkeley. Though the basic premise is to find new and compelling ways of using digital technology to enhance/enrich/change urban life, a wide array of viewpoints were presented, including largely non-computational ones.
I stashed my notes in meta's bag at the end of the day, and have waited too long now to retrieve them, so I'm going to try to do this from memory for now... Here were some of the highlights.
Dennis Crowley showed off his system dodgeball, which allows you to broadcast your location so your friends can find you. I've since signed up for the service, and it's interesting receiving location messages about your friends. As my friends seem to be using the system judiciously, no resulting awkward social situations have surfaced... yet.
Cassidy Curtis spoke about his excellent graffiti archaelogy project. I spoke with him briefly at the end of the day, and got to learn more about his process of documenting various actual and potential graffiti sites as well as his encounters with graffiti artists and cultures.
Jack Napier taught us how to improve the urban landscape through billboard liberation. Already an Adbusters fan, needless to say I was enthralled.
Anne Galloway took the stage to dispel any digital utopianism left amongst attendees. While techno-utopianism is an undercurrent of much of the human-computer interaction field, the ubiquitous computing literature is particularly full of unexamined (and, imho, in many (most?) cases unwarranted) optimism. Hopefully Anne's polemic helped kill that good and dead for those in attendance, promoting a balanced, critical perspective.
Paul Dourish speaks eloquently, insightfully, and quickly. His lesson (among others) - don't forget that cities are living things subject to continual interpretation and negotiation. Beware of succumbing to the temptations of positivist modeling in your urban computing endeavors.
Interesting anti-DRM talk from Cory Doctorow, given to Microsoft Research. I've just been reading Larry Lessig's latest book Free Culture (available for free under a CC license) and this talk covers similar ground and concepts.
The main claims:
1. That DRM systems don't work: if the recipient of an encrypted message and the attacker are the same person, you're doomed to failure.
2. That DRM systems are bad for society: honest people will remain honest, hence DRM only robs them of fair use.
3. That DRM systems are bad for business: open standards lead to new markets and new innovations.
4. That DRM systems are bad for artists: DRM flies in the face of the advantages of new media: more art with a wider reach.
5. That DRM is a bad business-move for MSFT: DRM will lose. So don't pour your money down the drain.
Researchers from Switzerland and South Africa have designed a visual interface that would give autonomous machines the equivalent of body language. The interface represents a machine's internal state in a way that makes it possible for observers to interpret the machine's behavior.
You can also check out the actual research paper: "Towards genuine machine autonomy". It's scarce on pictures, but enough to get a gist. Didn't strike me as earth-shattering, but if users can effectively use it to better understand and make inferences about machine behavior, I'd call it a win. Let's see more user studies!
When I first read scott's satirical announcement, my initial gut-reaction was off-putting... which lead me to investigate why. Upon reflecting, I feel that, rather than a reaction rooted in some latent google-philia, my discomfort comes from a fundamental disconnect between how e-mail works and how most folks conceptualize it.
Us computer scientists are so often used to thinking about these things in terms of their actual implementation. From a security (as opposed to privacy, whatever you mean by that) standpoint, all the mail carriers have capacity to do harm. We know that sending an e-mail is not like sending a sealed envelope. Focusing solely on mechanism, scott's analogy is only correct if the USPS also mandated that from now on people could only send postcards... no more envelopes! However, a small minority of informed users would start using ciphers which scramble the "publicly" visible contents of their postcards into gibberish that the postcard recipients could then decode.
Metaphorically, however, many if not most folks think of their electronic mail in terms of it's enveloped, physical counterpart. The real problem then, may not be that G-Mail does this or Hotmail does that, but that mechanism and metaphor are not mutually supporting.
Given a choice, I personally would uphold the metaphor over the mechanism. If people's expectation is that their private content remains private, perhaps it's time to consider ways to make the mechanism match up.
It's funny though, I was checking my mail on g-mail yesterday, and noticed two little adverts on the side of the page. Struck me at the time as so insignificant... but in light of the comments above it seems to me that if there is a problem here that is worthy of action, the illconceived yet well-intentioned efforts of Sen. Liz Figueroa and friends are attacking the symptoms rather than the source.
California State Senator Liz Figueroa (D) of Fremont is drafting legislation to stop Google's free e-mail service G-Mail, as she is under the impresssion that g-mail constitutes "an absolute invasion of privacy" due to its policy of using keywords in your e-mail to present targeted advertisements.
While I can understand the feature may be unsettling to those who don't understand how it is being achieved, this may be a case of a politician trying to legislate something they do not understand. Please people, a little research might be in order before you put your pen to paper. Only a computer sees the content of a g-mail e-mail, not Google employees. More importantly, Google's advertisers do not know anything about you nor have any access to you unless you choose to click their link and go to their site. G-Mail is also very clear and upfront about how and when e-mail data is used. Contrast that to Hotmail or Yahoo!, who provide banner ads that can allow advertisers to place cookies on your machine and track you across different websites.
Any online e-mail service has the potential for privacy violation. People's personal data are sitting on Yahoo! and MSN servers as well, leaving the same potential for within-company violations. Furthermore, as Kevin Fox has pointed out, both Yahoo! and Hotmail collect a ton more demographic info about you than G-Mail currently does. It is completely understandable that members of our society will at times be uncomfortable or uninformed about new technologies. It is not acceptable, however, for politicians to perpetuate misunderstandings, let alone attempt to inscribe them into law. Perhaps something like Derek Powazek's open letter will help focus Sen. Figueroa's perspective.
I do think there are important privacy concerns that this debate brings to light. When do machines "reading" our e-mail cross the line? If G-Mail is "bad", aren't spam filters (which scan our e-mail with greater sophistication) and Amazon's collaborative filtering violating our privacy as well? What levels of data mining are we comfortable with and which aren't we? These things need to be discussed and made subject to social negotiation, but knee-jerk legislation may short change people under the rubric of protecting them.
Another, larger, concern was raised earlier today in a conversation with Joe and Yuri. Yuri noted that what bothered him was having all his primary internet activities (i.e. search and e-mail) monitored by a single body. Given that this is the direction in which Google, Yahoo!, and Microsoft are all headed, I think he has a point. Safeguards for preventing "omniscient" companies from abusing people's data are not a bad idea (and one which normal market pressures might resolve, if people are properly educated on the matter). But legislation preventing useful technologies for the wrong reason doesn't help.
So while others were telling me I was falling victim to an April Fool's stunt, I instead got moving to try and procure my own g-mail account. Thanks to a friend, I just got my invite today, and so far I am impressed.
Here's a link to G-Mail's getting started page, which has info on the service. More first experiences and impressions are in the extended entry. I'm looking forward to using this service more and getting a deeper opinion, so e-mail me there (gmail.com), under the heerforce moniker.
First off, I get 1GB of mail space. Sweet. Next, the interface design is quite good, introducing great features while keeping a simple design. Google is pushing integrated search as a major feature, but since I just started the account, it was the other things that stood out.
One change from most e-mail clients is that g-mail automatically groups e-mail threads together into a single entry in your inbox. This means that when someone writes me, I reply, and then they write back, these are all grouped together and move to the top of the inbox when a new message arrives. Furthermore, when viewing an e-mail, all the previous messages in the thread are there, too, just waiting to be expanded with a single click. This includes all your replies, so no more digging through the sent mail folder if you don't want to. Reply and forward features are also integrated on the page, allowing you to respond in context (no new pages or windows popping up, unless you want to).
Another nice touch is that inbox entries don't just show the sender and title, they give a short list of the conversation history (i.e., not just the current sender, but previous ones as well), and after the title, the entry includes as much of the message body as fits. Other nice touches: instead of folders there are "labels" allowing multiple categorizations, auto-complete for address book entries (sorted by usage), integrated spell checking, and an easy flagging mechanism ("starred" mails) for keeping track of important messages.
All in all, it's a lot of little UI tweaks that I suspect will add up. It looks like the designers did a good job of optimizing the interface to make things faster and simpler. At this point I feel like a freakin' Google ad, but what can I say, I am impressed so far.
Which brings up the last point... Google includes ads along the side of the page, which are triggered by the content of your e-mail. While perhaps this may be unsettling to some, advertisers never see your content. After all, it's not as if Yahoo! or Hotmail can't read your content, too, and in those services the advertisers can actually use their banner ads to track you with cookies. G-mail's advertising is much more subtle... there are no annoying banner ads, and the text only ads, just like the ads on their search pages, are pretty easy to tune out.
...it pours. in addition to a social networking service (orkut) and personalized search, Google has also launched Gmail, it's own mail service -- including 1GB(!) of storage for free. They're in testing phase, though, so you can't just walk up and get an account yet.... unless you know the right people I guess. Anyway, looks to me like Google's engaging a new front in the search wars.
NOTE: In the comments below, bp points out that I may have fallen victim to an April Fool's trick. (but it was March 31, I says to myself). If so, my hat is off to Google for pulling a great one. Other victims would include ZDNet, New Scientist, c|net, the New York Times, and my local television news. How delightful! And in the case that it's for real, just the possibility of the hoax is a brilliant marketing device. Here's google's irreverent press release, dated April 1.
kwc notes that Google labs has launched a new personalized search feature and asks if it is the result of Google's acquisition of Kaltix. Indeed, it looks eerily familiar to a very cool demo I saw not long ago.
While manually setting up your own profile through a bunch of check boxes is a bit cumbersome, I have to give props to the Google/Kaltix folks for not requiring any login, or transfer of name, e-mail, etc, to use the service. I believe that Outride (another personalization firm acquired by Google) used user's web bookmarks and observed surfing behavior to seed personalization rankings, but Google has (wisely) decided to sidestep those privacy/trust issues for now. Not that determined corporations can't infer all sorts of things using cookies, but it's still a nice touch.
We'll see how long this stays a labs project, and what Google does if and when it decides to give these features official status. Regardless, it's great to see this stuff out in use and find out how people react to it. It should be also interesting to see if any good stories regarding unexpected 'personalized' search results start surfacing. (Will ad words eventually be personalized, too? I can imagine the Google version of the famous "Will you marry me?" stunt)
A cogent critique of experimental physics that had my material science roommates (who research germanium, of all things) in stitches. The most insightful line: This relation between temperature and resistivity can be shown to be exponential in certain temperature regimes by waving your hands and chanting "to first order". Interestingly, it appears this was written by the same person responsible for that very cool UIST paper from 2001 on techiques for creating custom interpolated clip art.
I've been working like a dog trying to get my master's work (a user interface toolkit for interactive graph visualization) wrapped up before I head out to Europe in April. Among other things, this has put quite the damper on the free cycles available for things like blogging, but the work is really starting to shape up. I've given talks on the work to groups at both Berkeley and PARC and have received some great feedback.
As a colleague of mine has taken to saying, "a toolkit is software where the interface is an API." So now I'm launching a user study to test the API of the toolkit by sitting programmers down and observing them build applications with it. So..... here comes the pitch..... If you're familiar with the Java programming language, have built Java Swing or AWT user interfaces, and (preferably) are comfortable with the Eclipse integrated development environment, please consider participating in my study. The study is being held at UC Berkeley and will last about an hour and forty-five minutes. Not only will you get exposure to an open-source software toolkit that may be useful to you, you will also be compensated for your time. Just e-mail me if you're interested.
With all the hoopla surrounding social network sites these days, I was a bit surprised to see that this one, perhaps overshadowed by the launch of orkut, seemed to fly under most folks' radar: Eurekster. Eurekster is a personalized search engine that uses the search activity of your social network to help rank your search results... like if Google took your friendsters into account when computing a personalized PageRank. The site got a feature in ZDNet a few weeks ago.
So I signed up a couple fake accounts to see how it works. The graphic design of the site left me feeling bored and uninspired, so fortunately the registration process was simple and quick, with no long list of interests or demographic data to fill out... just a name, e-mail, and password. Like friendster and any other YASNS they then ask you for a list of friend's e-mails to invite into your social network. You then use Eurekster like any search engine, except that search hits previously clicked-through by people in your social network climb up in the ratings, and are marked with the Eurekster 'e' logo to indicate the previous traffic. Additionally, a side bar on the right of the browser presents the most recent and most recurrent search queries and followed links.
Their business model for the moment is to collect money through paid search results provided by Overture. It's an interesting idea, but I don't expect them to do well. First, these kind of sites need a critical mass to be successful, and I don't think the cost of building up yet another social network will give you a reasonable benefit over what you can already get from Google. Besides, do I really want my friends' search results to influence mine? The voyeur in me kind of likes the idea of seeing the "footprints in the sand" of previous searches, but does it make my search results much more relevant? Perhaps if I could segment my friends into different groups, and apply these groups depending on topic, it might add some relevance, but that incurs even more work on the part of the user. There is also the possibility, especially in smaller networks, of spying other's search queries. Your social network can then play the game of "which one of us has been hunting for porn!?", though to be fair, Eurekster includes a "private search" checkbox that hides your searches from your network. Still, what about people following crappy links, both intentionally (search spamming!) and unintentionally, changing your results? Finally, before I get any further carried away, how big does your social network need to be for it to make any real, significant impact on the majority of your searches?
I think using actual user behavior to improve relevance rankings is a fruitful avenue to explore.... but why even bother with the social network? Why not just use the traffic patterns of everyone, or maybe just yourself? The most useful feature may actually be to have a social network consisting of just yourself, and then all the sites you visited before will rise in the rankings, allowing you to revisit them faster. In the case of one global network, with a little analysis or clustering you could even pick out global patterns and groupings which you could use to refine your search upon demand (though I suppose this is akin to adding user interaction data to a search engine like Vivisimo, which already does clustering). In the end, though, how will any of this successfully differentiate a competitor from Google? That's certainly a tough act to beat today, let alone in the future when Google unrolls their own personalization technology, based on the work they acquired from Outride and Kaltix.
I particularly enjoyed the anecdotes regarding hiring competition:
Last year, Rick Rashid, a Microsoft vice president in charge of the company's research division, came to its outpost in Silicon Valley to give a demonstration of an experimental Microsoft Research search engine. Shortly afterward, however, Mike Burrows, one of the original pioneers of Internet search at Digital Equipment who later helped design Microsoft's experimental search engine, quietly defected. He joined Google.
... Microsoft has already begun a recruitment campaign aimed at demoralizing Google employees, several Google executives said. Microsoft recruiters have been calling Google employees at home, urging them to join Microsoft and suggesting that their stock options will lose value once Microsoft enters the search market in a serious way.
...hmmm, seems a bit duplicitous for my tastes.
Here's a copy of the article:
Microsoft Is Taking On Google
By JOHN MARKOFF
Published: February 1, 2004
PALO ALTO, Calif.
AT the World Economic Forum in Switzerland last week, Microsoft, the software heavyweight, and Google, the scrappy Internet search company, eyed each other like wary prizefighters entering the ring.
Bill Gates, the chairman of Microsoft, stated his admiration for the "high level of I.Q." of Google's designers. "We took an approach that I now realize was wrong,'' he said of his company's earlier decision to ignore the search market. But, he added pointedly, "we will catch them.''
The four top Google executives attending the forum, at the ski resort of Davos, were no less obsessed with Mr. Gates's every move. "We had many opportunities to see Bill and Microsoft here in Davos," Eric E. Schmidt, Google's chief executive, wrote in an e-mail message to a colleague that was distributed to employees through an internal company mailing list.
Microsoft is intently poring over Google's portfolio of patents, hunting for potential vulnerabilities, Mr. Schmidt contended. And because Google is running its business using Linux - the free open source software that has become the biggest challenger of Windows - Microsoft is concerned that it may be at a competitive disadvantage. "Based on their visceral reactions to any discussions about 'open source,' '' Mr. Schmidt wrote in his e-mail message, "they are obsessed with open source as a business model.''
Get ready for Microsoft vs. Silicon Valley, Round 2.
The last time around, in the mid-1990's, Netscape Communications, another brash, high-tech start-up from the Bay Area, commercialized the Web browser, touching off the dot-com gold rush. The company told anyone who would listen that its newfangled software program would reduce Microsoft's flagship Windows operating system to a "slightly buggy set of device drivers.''
As it turned out, Microsoft - based in the Seattle suburb of Redmond, far from Silicon Valley, the heart of the nation's technology industry - was listening.
Mr. Gates, belatedly waking up to the threat that the Internet posed to his business, aimed Microsoft's firepower at Netscape and flattened his rival, which was later acquired by America Online and is now a shadow of its former self in an obscure corner of Time Warner.
As a consequence, however, he brought a federal antitrust lawsuit down upon his company, raising the specter of a Microsoft breakup. In the end, Microsoft escaped with little more than a requirement that it operate under a relatively mild court-ordered consent decree.
Today, nearly everyone in Silicon Valley, from venture capitalists and chip engineers to real estate agents and restaurateurs, has begun to ask: Will Google become the next Netscape?
Mr. Gates, who for more than a decade has promised - but not yet delivered - "information at your fingertips" for his customers, has decided that the Internet search business is both a serious threat and a valuable opportunity.
The co-founder and now the chief software architect of his company, Mr. Gates readily acknowledges these days that Microsoft "blew it" in the market for Internet search. Despite his early grand vision, he displayed little inclination to deploy software that would improve the ability of computer users to find information - until he saw the dollars in the business.
THAT opportunity fell to two Stanford computer science graduate students, Sergey Brin and Larry Page, who disregarded the industry's common wisdom that search technology would become an inexpensive, marginal commodity.
While the Internet's dominant companies fought one another over Web portals, the promise of e-commerce and access to providers like America Online, Google developed a speedy search engine that soon became almost a universal first step onto the Internet. It displaced earlier search engines because the technology invented by Mr. Brin and Mr. Page did a measurably better job in returning results that satisfied Web surfers' requests.
As a result, Google now has an immense number of users, with 200 million searches on an average day. That gives it a great advantage over its competitors, which are now trying to catch up.
"The system that has the most users benefits the most," said Nancy Blachman, a computer scientist and author of an independent guide to using Google (www.googleguide.com). "Microsoft faces a tremendous challenge because Google fine-tunes its system by watching how users adjust their queries."
But Google has done more than develop a smart new technology. Unlike many dot-com flameouts of the 1990's, it has also figured out how to turn it into a highly profitable business. The company demonstrated that focused ads based on key words related to Web surfers' search requests are the most effective form of online advertising.
That has ignited a three-way battle among Microsoft and its two Silicon Valley rivals: Yahoo, based in Sunnyvale, Calif., and Google, whose headquarters are nearby, in Mountain View. Underscoring the importance of search engines to Internet advertising, Yahoo recently said it planned to end its exclusive reliance on Google for search results and had established its own research lab to try to cut its new rival's lead.
Google's financial success is clear. In 2001, the company had virtually no revenue; in the past year, it recorded sales of almost $1 billion and profits of about $350 million, according to several executives familiar with the company's private financial figures.
As for Microsoft, its executives have already begun boasting about sharp revenue growth from Internet advertising from its MSN partnership with Overture, now a Yahoo division, which also pioneered Web search advertising. In its second fiscal quarter that ended on Dec. 31, Microsoft reported $292 million in online advertising, an increase of 47 percent from the corresponding period a year earlier. The company has said that its overall online advertising revenue, which includes sources beyond search ads, reached $1 billion in the past year.
Later this year, Microsoft is expected to unveil its own search technology, which Mr. Gates says will help Microsoft catch up with Google. Last week, Microsoft released a test version of a special set of software buttons for its browser designed to direct users to its MSN search and related services. For Google, though, the greater threat is that Microsoft will decide that Internet search, like the Web browser before it, should be an integral part of future versions of the Windows operating system.
For the moment, though, Google's lead seems formidable. Last year, Rick Rashid, a Microsoft vice president in charge of the company's research division, came to its outpost in Silicon Valley to give a demonstration of an experimental Microsoft Research search engine. Shortly afterward, however, Mike Burrows, one of the original pioneers of Internet search at Digital Equipment who later helped design Microsoft's experimental search engine, quietly defected. He joined Google.
But even if it can protect its technological lead, will Google still succumb to Microsoft's marketing muscle?
Google shares the intense Silicon Valley work ethic that characterized companies like Netscape. Its new headquarters, on a spacious campus once occupied by SGI, a computer maker, are just across the freeway from Netscape's original base.
But many veteran Silicon Valley executives are skeptical about Google's ability to hold its corporate culture together once it goes public later this year. The initial public offering, much anticipated, is expected to create hundreds of instant multimillionaires among its regular employees, but will leave many others hired as contractors without significant gains. As a result, some people fret that Google is fostering a class society in its ranks.
So far, though, the disaffection is limited largely to the company's Adwords business, which is aimed at creating and placing its focused search advertising. That operation has grown rapidly with temporary workers. "The Adwords environment is brutal," one Google executive said.
Clearly, though, keeping its ebullient esprit de corps so robust after the I.P.O. will be difficult, say those who have gone through similar roller-coaster rides in Silicon Valley.
"The challenge Google faces is figuring out how to retain a high rate of innovation" in the face of a disruptive event like the I.P.O., said a former Netscape executive, who also worries that the two young founders, for all their brilliance, may not fit well into the kind of management team needed to run Google as a fast-growing public company.
Although Google has clear vulnerabilities, Microsoft is seen in Silicon Valley as a powerful but not particularly creative competitor. Beyond its core business in Office and Windows, Microsoft has no major recent successes to point to - but it has a growing list of disappointments. These include its Xbox video game player and Ultimate TV set-top box.
In other words, rivals have fought Microsoft and lived to tell about it. "At TiVo, we managed to stare down that $40 billion barrel,'' said Stewart Alsop, a venture capitalist who helped finance the creation of TiVo's digital video recorder, which allows TV viewers to easily record hours of video programming for viewing at other times. "We dodged that particular bullet,'' Mr. Alsop said, when Microsoft "shut down Ultimate TV and got out of the business."
Other executives who compete with Microsoft said Google's position might be more defensible than Microsoft executives believe.
"The good news for Google is that what they do has many branches," said Rob Glaser, the chief executive of RealNetworks, which competes with Microsoft in the software for playing video and digital audio on personal computers. "It's not easily replicable in one step."
OTHERS say that even though the Justice Department consent decree is weak, it may still be enough of a barrier to prohibit Microsoft from making Internet search an integral part of the operating system in the same way it absorbed the Web browser.
"They can't undercut Google on price, and I don't think they can get away with integrating search," said S. Jerrold Kaplan, an industry executive who competed against Microsoft while at Lotus, the spreadsheet maker that is now part of I.B.M.
As it prepares its public offering, Google is trying to avoid Netscape's fate by remaining focused on its own measures of customer satisfaction. On computers at Google headquarters, the home page constantly displays a graph reflecting how well Google does on searches, compared with its competitors. Even the slightest dip in performance creates alarm, a company executive said.
Google has also brought in a Silicon Valley veteran, William V. Campbell, the chairman of Intuit, to serve as a consultant. His gospel for Googlers, as employees refer to themselves, is this: Ignore Microsoft's impending arrival as a competitor and focus on the customer.
Good luck. Microsoft has already begun a recruitment campaign aimed at demoralizing Google employees, several Google executives said. Microsoft recruiters have been calling Google employees at home, urging them to join Microsoft and suggesting that their stock options will lose value once Microsoft enters the search market in a serious way.
"Our approach has been to seek out the best and brightest talent," said Lisa Gurry, a lead product manager at MSN. "Beyond that, I can't add anything."
Google executives also say they believe that Microsoft is systematically pursuing Web sites downgraded by Google, which punishes companies for trying to manipulate their rankings. The company is striking partnerships with unhappy Google customers.
Microsoft is currently relying on Overture for its paid search listings, Ms. Gurry said.
But Google is hardly standing still. As Mr. Gates himself has acknowledged, it has marshaled a remarkable collection of technologists. They are focused both on keeping the company's lead in search technology and on developing a range of new services.
To help their work, Google has been quietly developing what industry experts consider to be the world's largest computing facility. Last spring, Google had more than 50,000 computers distributed in over a dozen computer centers around the world. The number topped 100,000 by Thanksgiving, according to a person who has detailed knowledge of the Google computing data center. The company is placing a significant bet that Microsoft will be hard pressed to match its response time to the ever increasing torrent of search requests.
Besides the additional computing firepower, Google has a wide-ranging list of new services that it will roll out as competition with Microsoft and Yahoo dictates. For example, it recently introduced Orkut, a social networking service intended to compete with Friendster, LinkedIn and others. Still under wraps is an electronic mail service that will have an advertising component.
The company has also been pushing hard to find new sources of information to index, beyond material that is already stored in a digital form. In December, it began an experiment with book publishers to index parts of books, reviews and other bibliographic information for Web surfers.
And Google has embarked on an ambitious secret effort known as Project Ocean, according to a person involved with the operation. With the cooperation of Stanford University, the company now plans to digitize the entire collection of the vast Stanford Library published before 1923, which is no longer limited by copyright restrictions. The project could add millions of digitized books that would be available exclusively via Google.
ON the marketing side, the company is racing to build its strengths overseas. Wayne Rosing, vice president for engineering at Google, has been chosen to travel the world, weaving the company's search engine into local economies and local technologies. It is concentrating initially on 12 countries.
Mr. Page, the Google co-founder, is even trying to persuade Mr. Schmidt, the veteran Silicon Valley executive recruited from Novell Inc., to run Google, and others in the company to market a phone with a built-in custom personal digital assistant intended to let Web surfers use Google from anywhere.
For all of Google's hyperactivity, there is still a lingering sense among many Silicon Valley veterans that they have seen this movie before. The company may not have Netscape's arrogance, but it is still not clear that all of its clever marketing, technology and brand identification can withstand Microsoft's onslaught when it arrives.
After all, just as Silicon Valley has learned from some of its errors, so has Mr. Gates. In Davos, Mr. Gates ruefully acknowledged that Google "kicked our butts,'' reminding him of what Microsoft itself was like two decades ago.
"Our strategy was to do a good job on the 80 percent of common queries and ignore the other stuff,'' he said. But "it's the remaining 20 percent that counts,'' he added, "because that's where the quality perception is.''
Brown is one of the most mysterious colors. Brown is dark yellow. While people talk about a light green or a dark green, a light blue or a dark blue, yellow is different. When colors in the vicinity of yellow and orange yellow are darkened, they turn to shades of brown and olive green. Unlike red, blue, and green, brown requires that there be a reference white somewhere in the vicinity for it to be perceived...
Crazy. Despite all my work with interfaces, visualization, and design, it took reading this passage for me to realize that, spectrally speaking, brown is really dark yellow. So why its distinct appearance? (And have you ever seen a brown light??)
One thought I had is based on the opponent process theory of vision, in which colors are perceptually arranged along three dimensions: a red-green spectrum, a blue-yellow spectrum, and a white-black (luminance or brightness) spectrum. Most people have three kinds of color receptors (called cones), roughly corresponding to the wavelengths for red, green, and blue light. Yellow is perceived through the sum of the higher wavelength (red and green) receptors. Since yellow is an inferred primary color, not the result of a specific color receptor, perhaps that has some bearing on why in lower luminance it has this weird perceptual transformation to brown.
Then a second thought occurred to me. Maybe it's an evolutionary feature that unmistakenly lets us know shit when we see it.
I was first exposed to electric paper through the ground-breaking work of the late 90's done at Xerox PARC, peddled today by spin out company Gyricon. Now Philips has unveiled the most flexible display yet. I would really love to start designing user interfaces for this stuff. Sadly, the refresh rate is currently a lowly 1 Hertz, though I doubt it will stay there for long. So researchers, while you're at it, don't forget the touch sensing. We'll definitely need to get us some of that, too...
And so we take one more nanometer-sized step towards the Diamond Age... perhaps our children will have Illustrated Primers of their own.
someone once explained to me a rather plausible theory as to why geeks make the best lovers. if you are among those who are confused by this (uninitiated, perhaps?), this comic may be enlightening.
Ah, even more geekiness for today: The 5 Commandments supposedly describing our technological process. They are:
MOORE'S LAW: The number of transistors on a processor doubles every 18 months ROCK'S LAW: The cost of semiconductor tools doubles every four years MACHRONE'S LAW: The PC you want to buy will always be $5000 METCALFE'S LAW: A network's value grows proportionately to the number of its users squared WIRTH'S LAW: Software is slowing faster than hardware is accelerating
None of these are particularly rigid... read the article for lots of exceptions to these rules. The end of the article even mentions Jakob Nielsen's attempt at such a law... Nielsen's Law of Internet Bandwidth: a high-end user's connection speed to the Internet will grow by 50 percent per year, but Web site developers won't get to take advantage of this added bandwidth to make Web pages larger until 2003.
I wish my connection got 50 percent faster per year; my DSL got 50 percent slower when I moved to another neighborhood. The first part of the law seems rather suspect and possibly misleading... it may be more accurate to phrase the law in terms of infrastructural cycles (e.g., modem -> dsl/cable -> fiber optic? -> ???). Perhaps the annualized averages over these jumps works out as he says... but it doesn't help for the 3-4 years you sit at one speed waiting for the next.
SJ Mercury News has printed up 10 tech trends for 2004. For the impatient, here is the 10 second version:
Bluetooth - local area wireless components Megapixel phones - reach out and touch someone, in high-res iPod's competition - Dell's cheaper iPod knock-off and its friends Video iPods - movies on the go? Faster cell networks - for Verizon and AT&T, anyway Surveillance - go Ashcroft go Video blogs - vidblogs, vogs, vlogs? Big, flat cheaper TVs - sit on your ass in high definition DVR + DVD-R - record your favorite shows and movies, and archive them, too
An easy to read legal explanation of open source software, posted at groklaw and more recently on slashdot. I'm posting it here for my own future reference.
Understanding Open Source Software - by Red Hat's Mark Webbink, Esq.
Wednesday, December 31 2003 @ 09:20 AM EST
Here is a good article to share with your boss.
Mark Webbink, Senior Vice President and General Counsel of Red Hat, Inc., wrote this article for corporate attorneys, explaining free and open source software and comparing various open source licenses, detailing how the GPL really works, explaining US copyright law, and listing some corporate law office best practices for software, from the standpoint of what policies are prudent for the corporate environment.
He also explains how derivative works are defined, touches on the indemnification issue and the difference between open source and "shared source", and highlights some of the main myths and misconceptions about the GPL and open source.
I get email about this subject, so I know some of you are very interested in this subject, so I hope you enjoy finding answers in this thorough and accessible information.
This article was originally published in the March 2003 Journal of the New South Wales Society for Computers and the Law, and we republish with Mr. Webbink's kind permission.
The Open Source Initiative ("OSI") defines Open Source as software providing the following rights and obligations:
1. No royalty or other fee imposed upon redistribution.
2. Availability of the source code.
3. Right to create modifications and derivative works.
4. May require modified versions to be distributed as the original version plus patches.
5. No discrimination against persons or groups.
6. No discrimination against fields of endeavour.
7. All rights granted must flow through to/with redistributed versions.
8. The license applies to the program as a whole and each of its components.
9. The license must not restrict other software, thus permitting the distribution of open source and closed source software together.
This definition clearly leaves room for a wide variety of licenses, and we will examine a number of those license types shortly. Although it is this OSI definition of Open Source to which the remainder of this paper relates, it is worthwhile to also examine the definition of Free Software, for often times the terms Free Software and Open Source are used interchangeably. While they are similar, there are differences worth appreciating.
When we speak of Free Software, we are not talking about freeware, i.e., software that is essentially in the public domain. Rather, we are talking about software that is licensed under the precepts of the Free Software Foundation ("FSF") and its flagship GNU General Public License.
According to the FSF definition:
"Free software is a matter of the users' freedom to run, copy, distribute, study, change and improve the software. More precisely, it refers to four kinds of freedom, for the users of the software:
1. The freedom to run the program, for any purpose (freedom 0).
2. The freedom to study how the program works, and adapt it to your needs (freedom 1). Access to the source code is a precondition for this.
3. The freedom to redistribute copies so you can help your neighbour (freedom 2).
4. The freedom to improve the program, and release your improvements to the public, so that the whole community benefits (freedom 3). Access to the source code is a precondition for this.
A program is free software if users have all of these freedoms."
Contrasting the Open Source and Free Software definitions, one finds that all Free Software is Open Source, but as administered by the Free Software Foundation, not all Open Source is Free Software. The difference principally arises from so-called license compatibility, but in large measure the differences are principally philosophical and not substantial.
Fundamentals of Copyright Law
To better appreciate Open Source software, we need a basic understanding of copyright law. Open source software is fundamentally grounded in copyright law[1] . In order to appreciate the rights granted under Open Source licenses, one must first be familiar with the basic bundle of rights granted to the holder of a copyright. Under U.S. copyright law, those rights are:
1. The exclusive right to copy the work;
2. The exclusive right to make derivative works;
3. The exclusive right to distribute the work;
4. The exclusive right to perform the work; and
5. The exclusive right to display the work.[2]
These rights, in turn, are subject to certain limitations, such as rights of "fair use." Fair use includes the use of a work for purposes of criticism, comment, news reporting, teaching, scholarship or research and does not constitute infringement of the work. Whether a specific use is fair use is determined by a number of factors, including:
(1) the purpose and character of the use, including whether such use is of a commercial nature or is for nonprofit educational purposes;
(2) the nature of the copyrighted work;
(3) the amount and substantiality of the portion used in relation to the copyrighted work as a whole; and
(4) the effect of the use upon the potential market for or value of the copyrighted work.[3]
Works, such as software, may be placed in the public domain and exist outside of the scope of copyright law.[4] However, with changes in the copyright law in the 1970's and 1980's, including the automatic application of copyright under the Berne Convention, it is no longer an easy task to contribute software to the public domain.[5] Software (or any other body of work) that is in the public domain cannot, by definition, assert any restrictions on who or how it can be used, modified or distributed (though other laws, such as export controls, may still restrict some software's use or distribution). If Open Source software were in the public domain (that is, not subject to copyright because the author has disclaimed copyright in the work), any business or individual could use the software for any purpose without any copyright restriction, and there would be no requirements for legal review above and beyond ensuring compliance with other statutes (which apply equally to all other software, public domain, or not). Because Open Source software is not in the public domain, but instead protected by copyright law and licensed for use under certain, perhaps unconventional, terms, those terms must be understood.
A valid copyright license applies to a body of work and must assert at least one restriction. A copyright license that states no restrictions implicitly grants all rights, including rights to use, modify, distribute, etc. Most proprietary software copyright licenses assert restrictions on use (including definitions of "fair use", which, according to such licenses, usually does not include decompiling, reverse engineering, or other such uses), copying (usually only for the purposes of backup), and redistribution (usually only when acting as an authorized agent for the copyright owner).
Types of Open Source Licenses
Open source licenses may be broadly categorized into the following types: (1) those that apply no restrictions on the distribution of derivative works (we will call these Non-Protective Licenses because they do not protect the code from being used in non-Open Source applications); and (2) those that do apply such restrictions (we will call these Protective Licenses because they ensure that the code will always remain open/free).
To better appreciate the nature of these licenses, it is helpful to picture software licenses on a continuum based on the rights in copyright extended to the licensee. See Diagram 1 at the conclusion of this article.
Software that has been placed in the public domain is free of all restrictions, all rights under copyright having been granted to the public at large. Licensors of Non-Protective Open Source licenses retain their copyright, but they grant all rights under copyright to the licensee. Licensors of Protective Open Source licenses retain their copyright, grant all rights under copyright to the licensee, but apply at least one restriction, typically that the redistribution of the software, whether modified or unmodified, must be under the same license. Licensors of propriety licenses retain their copyright and only grant a few rights under copyright, typically only the rights to perform and display. The following table, where the BSD license is used as an example of a Non-Protective Open Source license and the GNU General Public License as an example of a Protective Open Source license, displays these contrasts - see Diagram 2 at the conclusion of this article.
Non-Protective Open Source licenses include: Academic Free License v.1.2; Apache Software License v.1.1; Artistic; Attribution Assurance license; BSD License; Eiffel Forum License; Intel Open Source License for CDSA/CSSM Implementation; MIT License; Open Group Test Suite License; Q Public License v.1.0; Sleepycat License; Sun Industry Standards Source License; University of Illinois/NCSA Open Source License; Vovida Software License v.1.0; W3C Software Notice and License; X.Net, Inc. License; zlib/libpng License; and Zope Public License v.2.0.
Protective Open Source licenses include: Apple Public Source License v.1.2; Artistic License; Common Public License v.1.0; GNU General Public License v.2.0; GNU Lesser General Public License v.2.1; IBM Public License v.1.0; Jabber Open Source License v.1.0; MITRE Collaborative Virtual Workspace License; Motosoto Open Source License v.0.9.1; Mozilla Public License v.1.0 and v.1.1; Nethack General Public License; Noika Open Source License v.1.0a; OCLC Research Public License v.1.0; Open Software License v.1.1; Python License; Python Software Foundation License v.2.1.1; Ricoh Source Code Public License v.1.0; and Sun Public License v.1.0.
All of these, and additional new licenses, can be found on the Open Source Initiative website.
Some Open Source licenses of both types include other provisions, such as restrictions on the use of trademarks, express grants of license with respect to applicable patents, disclaimers of warranties, indemnification of copyright holders in commercial distributions, and disclaimers of liability. However, none of these provisions are as fundamentally important as the obligations/restrictions that are imposed on redistribution rights under the Protective Open Source licenses, and it is with those restrictions on redistribution that we next focus.
The GNU General Public License
As of this writing, the GNU General Public License ("GPL") is the most pervasive license of Open Source software. Of all the software to which it has been applied, none is better known than the Linux® kernel. In fact, the GPL has been applied to a majority of those software modules that are included in the best known of the Linux® distributions, such as Red Hat® Linux®. Its wide appeal among the Open Source community stems from the fact that it falls into that category of Open Source licenses which obligate parties who wish to redistribute such software, either in original or modified (derivative) form, to do so under the terms of the license agreement under which such software was received (all of which we refer to as Protective licenses). That is, having been granted the right to use, modify and redistribute the software under the GPL, the GPL requires you to extend those same privileges under the same terms to others who receive the software from you. This is the common thread that governs Protective licenses, and for that reason, we will focus on the GPL as the standard for Protective licenses.
The GPL provides certain rights to anyone receiving a license to software governed by the GPL. At the same time, it imposes very few obligations except on those who wish to redistribute the software: Those rights and obligations are:
1. The right to copy and redistribute so long as you include a copyright notice and a disclaimer of warranties. You may charge for the cost of distribution and you may offer warranty protection for a fee.
2. The right to make derivative works for your own use.
3. The right to distribute derivative works so long as you:
1. Identify the work as modified;
2. License it under the GPL; and
3. Provide the license information interactively if the program normally runs interactively.
This section, and the obligation to license under the GPL, does not apply to works which are independent works distributed with the GPL'd work and which run on the GPL'd works.
4. You may distribute the work only in executable form so long as the source code is:
1. distributed with the object code;
2. offered by a written offer, valid for a period of at least three years, to make the source code available for no more than the cost of distribution; and
3. for non-commercial distributions, accompanied with the offer the redistributing party received as to the availability of the source code.
5. You may not impose restrictions on any of these rights.
This is a simple, yet elegant approach. Basically, the licensor is permitting any licensee to exercise virtually all of the rights available under copyright, i.e., the right to copy, the right to make derivative works, the right to distribute, the right to perform, the right to display. The only obligation imposed is, if the licensee, in turn, wishes to distribute the software to other parties, they agree to do so only under the GPL. The sole purpose of these restrictions is to preserve the integrity of the original grant of freedom through any path of redistribution and to make it impossible for anybody to create a version of the software that offers less freedom to any recipient than the original version would have granted. To paraphrase, the GPL states "once free, always free."
Note that the GPL has no relevance to the case where a party licenses the software and chooses not to redistribute it. This is true whether the party is an individual, a corporation, a corporate conglomerate, or the government. As noted by the FSF, when the GPL refers to "You" in the context of a corporation, it means the parent company and all of the controlled subsidiaries of that parent. Similarly, when "You" is addressing a unit of government, it means that unit of government and all of the subdivisions of that government that are under the direct control of that government. In that context, "You" can readily mean the entire federal government of the U.S. or it could mean any state or commonwealth government, including the agencies of that state or commonwealth government. The GPL does not require that a licensee, who has not made a distribution of the software to another, provide copies of that software to any party who so demands it. The restrictions of the GPL apply only in the case of where GPL'd software is being provided to another party, and the GPL pertains only to the preservation of its original purpose-nothing more.
Based on the foregoing, we can divide the types of Open Source usage into categories, and analyze the legal implications of the GPL for each category. The interesting categories are:
1. Users who use only GPL binaries as they would any other similar program;
2. Users who modify GPL sources to handle local configuration issues or to address internal requirements and not for distribution to others; and
3. Users who modify GPL sources and redistribute them for fun and/or profit.
In case (1), the GPL affects these users not at all; use of the Open Source GNU Emacs TM text editor does not imply that the act of saving a file changes the ownership of the file to the FSF, nor does compilation of a file by Open Source GNU C Compiler cause the resulting object code to belong to the FSF, nor does setting a breakpoint in an executable cause the executable to suddenly become the property of the FSF. Thus, the normal use of GPL software (i.e., use like one would use any other commercial software) in a commercial environment poses no extraordinary legal problems. The wide distribution of Linux operating system software in the last several years for use on commercial web and enterprise servers is ample evidence that there is no legal reason to not use Open Source software if you happen to think it is better than the proprietary alternatives.
In case (2), the locally modified software by definition confers to its users access to the locally modified sources. There is no requirement within the GPL that such local modifications be disclosed to any other party.
In case (3), we get to the group of users for whom the GPL was really written. Users redistributing modified or unmodified versions of Open Source software must obey the GPL's "Golden Rule" of licensing the distributed software under the GPL and not adding any downstream restrictions. To the extent that somebody wants to profit from GPL'd software by using traditional proprietary license restrictions, those restrictions will prove difficult if not impossible to apply. Note, however, earning profit because of the GPL is both legal and encouraged.
From this analysis we are left needing a definition of what constitutes a derivative work in software.
What is a Derivative Work?
The U.S. Copyright Act defines a derivative work as:
"a work based upon one or more preexisting works, such as a translation, musical arrangement, dramatization, fictionalization, motion picture version, sound recording, art reproduction, abridgment, condensation, or any other form in which a work may be recast, transformed, or adapted. A work consisting of editorial revisions, annotations, elaborations, or other modifications, which, as a whole, represent an original work of authorship, is a "derivative work"."[6]
Thus, a work that is based on one or more preexisting works constitutes a derivative work to the extent that the new material added constitutes an original work of authorship. Such new material may include editorial revisions, annotations, elaborations or other modifications. Derivative works may transform the original work, such as in a translation, including translating software from one computer language to another, or they may combine the original work with other works, such as in a compilation like Red Hat® Linux®. Copyright protection in a derivative work or compilation extends only to the material contributed by the author of such work, and does not grant rights in preexisting material included in the new work.[7]
Where does the law stand on derivative works in software?[8]
The law on derivative works in software is not well established. The U.S. Copyright Act does not specifically address derivative works in software, and there are no U.S. Supreme Court cases immediately on point. Most of the case law has developed among the various U.S. Courts of Appeals, but even there the law varies from one circuit to the next.
The Copyright Act provides an important definition in addition to that of "derivative works", that of "computer programs", which are defined as:
"a set of statements or instructions to be used directly or indirectly in a computer in order to bring about a certain result."[9]
In addition, the Copyright Act limits the scope of what is covered by copyright by excluding certain subject matter. §102(b) of the Act provides:
"In no case does copyright protection for an original work of authorship extend to any idea, procedure, process, system, method of operation, concept, principle, or discovery, regardless of the form in which it is described, explained, illustrated, or embodied in such work."
Perhaps the most established of the tests for derivative works in software is the "abstraction, filtration, and comparison" ("AFC") test established by the Second Circuit.[10] Under the threepart AFC test, a court first determines (abstracts) the constituent structural parts of the original program. From these structural parts, the court then filters all unprotectable portions, including those unprotectable matters defined in §102(b) of the Copyright Act and elements that are in the public domain. In the final step, the Court compares any remaining code containing creative expression to the structure of the second program to determine whether the software program in question is sufficiently similar to the pre-existing work to justify a finding that the second program is a derivative work of the first. This AFC approach has been adopted by three other circuits: the Fifth,[11] Tenth[12] and Eleventh.[13]
Of the remaining nine U.S. Courts of Appeal, only one has adopted a clear test for derivative works in software. The Ninth Circuit's test is based on analytical dissection, which first considers whether there are substantial similarities in both the ideas and expressions of the two works and then utilizes analytic dissection to determine whether any similar features are protected by copyright.[14] The similar elements are categorized by the degree of protection they are to be afforded. "Thin" protection is afforded to non-copyrightable facts or ideas that derive copyright protection only from the manner in which those facts or ideas are aligned and presented. "Broad" protection is afforded to copyrightable expression. The court uses these standards to make a subjective comparison of the works to determine whether, as a whole, they are sufficiently similar to justify a finding that one is a derivative work of the other.
How do these tests apply to derivative works in Open Source software?
In addressing derivative works, Open Source software requires special consideration. This is due principally to the fact that Open Source software, by definition, permits the making of derivative works. Under a Non-Protective license, the new portions of such a derivative work may be licensed under the license of choice of the author, and there is little likelihood of an infringement dispute.
The case is much different with a Protective license because it requires derivative works to be licensed under the same license as the original work. Here the question largely becomes one degree of copying versus adequate avoidance of derivation. Where Open Source software licensed under a Protective license appears to have been copied, in whole or in part, into a larger work, which is then licensed under a different license than the original work, the question of derivative work and infringement would be determined by the courts using the tests outlined above. However, this is not the case where the subsequent author maintains the original Protective license with respect to the original work but licenses the new work under a different license, for here the subsequent author has not infringed the rights of the original author except to the extent that the new work can be determined to be a derivative work of the original. This latter instance requires an entirely different approach to determining derivation.
Where the original work continues to be licensed under a Protective license and the new work is licensed under an alternative license, the following factors are to be considered when determining whether the new work is a derivative of the original:
1. The substantiality of the new work;
2. Whether any part of the original work has been modified; and
3. How such modification has been accomplished.
This analysis is consistent with the distinction drawn by the GPL itself. Clause 2 of the GPL states:
"Thus, it is not the intent of this section to claim rights or contest your rights to work written entirely by you; rather the intent is to exercise the right to control the distribution of derivative or collective works based on the Program. In addition, mere aggregation of another work not based on the Program with the Program (or with a work based on the Program) on a volume of storage or distribution medium does not bring the other work under the scope of this license."
For example, if the work in question is a database written entirely by you, and the Program in question is a GPL'd operating system (one of many to which the database may have been ported), the distribution of the database with the operating system on a volume of storage (such as the system hard disk) would not confer the GPL of the operating system to the database software. On the other hand, if modifications are made to the Program (the operating system) in order to accommodate the work (the database), then those modifications, which are a derivative work of the Program, would need to be made available under the GPL. No modifications to the work (the database) need be redistributed in this case.
In summary, the legal requirements of the GPL are quite straightforward for commercial software providers: if you want to use a proprietary revenue capture model, keep your works (i.e., the code) separate from GPL'd works, keep the modifications made to each fully independent, and there will be no problems protecting your primary works. At the same time, any modifications you make to software that are already covered by the GPL will be subject to the GPL.
Myths About Open Source
Before leaving this discussion of Open Source licensing it is worthwhile to address some of the myths or misconceptions that have arisen around Open Source.
Myth 1 - Open Source software is "viral" and undermines intellectual property rights.
This myth is particularly rich. First, as already noted, Open Source software is fundamentally grounded in copyright law. As with the holder of any copyright, the copyright holder for a piece of Open Source software gets to elect which rights he/she will grant to others. Open Source authors simply choose to grant more rights than proprietary vendors. The mere fact that an Open Source author using a Protective license insists that derivative works that are distributed to others be licensed under the same license should be contrasted with proprietary software licenses that simply deny the licensee the right to create derivative works or to redistribute them. Each is an exercise in intellectual property rights, and neither is wrong.
Myth 2 - Open Source software is more prone to claims of intellectual property infringement.
The suggestion of the proprietary vendor is that, because the Open Source development model relies on a vast network of Open Source developers who are not necessarily under the control of the distributor, the code produced is far more likely to be exposed to intellectual property infringement claims. The facts simply do not bear this out. While there undeniably have been such claims against some Open Source development projects and/or distributors, the claims have been few and far between.
Myth 3 - Unlike proprietary vendors, Open Source software vendors do not provide warranties or indemnity against intellectual property infringement.
That is true, but no more true for Open Source vendors than for proprietary vendors. For example, the Windows 98 license expressly disclaims any warranty of non-infringement.
Myth 4 - The GNU General Public License is risky because it has never been tested in court.
True again. But which is riskier, licensing practices that are constantly being challenged or those that, in their simplicity and effectiveness, have avoided challenge.
Myth 5 - Making your source code viewable to some users is the equivalent of Open Source.
Open Source provides value to its customers and users by giving them total control over their computing environments. The customer gets to choose whether to run the standard version or whether modifications are desirable. The customer can not only see the bugs, he/she can fix the bugs. Making source code merely viewable to a few users does not help them understand the code, does not let them modify the code, and most importantly, does not let them fix the code when it breaks. This approach to source code "sharing" equates to entering a public library only to find there is no card catalogue and all of the books are in locked glass cases. Yes, you can root around and find the titles of the books, but you have no ability to gain knowledge from them. Proprietary software seeks to maximize its value solely in monetary terms by achieving a monopoly. Open Source software maximizes its value by assuring that a monopoly cannot be achieved.
Myth 6 - Open Source methods do not produce innovation.
This is a myth. The Open Source community: (a) developed the Apache webserver which is used to run the majority of webservers in the world today; (b) developed Sendmail, the most popular e-mail management software; and (c) developed BIND, the basis for using domain names instead of IP addresses to locate websites. Clearly, Open Source is capable of advancing the art of software.
Without belaboring this point, let us turn to best practices that a corporate law office should maintain with respect to software, whether Open Source or proprietary.
Corporate Law Office Best Practices for Software
As with any form of intellectual property, there are risks associated with licensing the use of software. Some of those risks may relate specifically to Open Source software, but most often they relate to all software, regardless of the form of license. Following are a series of best practices that every corporate law office should implement across their company:
1. Do not permit the uncontrolled importation of software onto company computers.
Do not permit employees to download freeware, shareware, or Open Source software onto company computers without first clearing the license terms with the legal department. At the same time, bar the use of proprietary software except to the extent that the company can account for the permitted licenses. In other words, know what you are putting on your machines--to do otherwise exposes your company to risk.
2. Deal with reputable software vendors with financial staying power.
One of the biggest risks a company takes is adopting software that has no future. Equally true is licensing software from a company without the financial wherewithal to maintain and protect that software. Know your vendors. Know their financial strength, know their policies on licensing, know their responsiveness, and know that their software is reliable.
3. Know how the software will be used.
It's one thing if Open Source is to be used as an operating system on a backoffice server, it is something altogether different if that same Open Source software is to be modified and embedded in a product. The former is not problematic; the latter may be. At the same time, make sure your IT folks are well aware of the typical proprietary restrictions which prohibit reverse engineering or modification. While some proprietary vendors may permit such activities under a special development license or a community source code license, they do not generally permit the activities under their general commercial licenses. It may be worthwhile to categorize each item of software and its permitted uses, e.g., approved for general use in executable form only, approved for use at the source code level in specialized applications or modified applications, and not approved for any use. Finally, nature of use is important in knowing whether the software will be distributed outside the company, potentially triggering Open Source licensing restrictions.
4. Have a means for documenting what software, and what version of that software, is in use.
Knowing this information and having ready access to it will help assure licensing compliance and at the same time permit IT managers the ability to manage the IT architecture and its advancement.
5. Require documentation of all internal software development projects.
This includes modification of Open Source software. Such documentation should indicate the source of any base software that is modified, all of the authors of the developed software, prior projects (both internal and with prior employers) on which such developers worked, and the identification of any known related intellectual property, particularly patents.
These are but a few suggestions. They are meant to address those issues most commonly found in software, including Open Source software.
For those interested in learning more about Open Source, the following websites are suggested reading:
* Free Software Foundation - http://www.fsf.org
* Open Source Initiative - http://www.opensource.org
* Technical FAQs on Linux from IBM - http://www-106.ibm.com/developerworks/linux/library/l-faq/?open&l=252,t=grl,p=LinuxFAQ
* Link to whitepapers on the legality of the GPL - http://www.newtechusa.com/Viewpoints/GPLLegalityLinks.asp
* Quick Reference for Choosing a Free Software License - http://zooko.com/license_quick_ref.html
* Why Open Source Software - http://www.dwheeler.com/oss_fs_why.html
* Linux Security - http://www.linuxsecurity.com
Footnotes
1. When I talk about copyright law in this paper, I am discussing U.S. copyright law as embodied in Title 17 of the United States Code. The United States is a signatory to the Berne Convention covering copyright, and much of U.S. copyright law is very similar to that of other Berne signatory countries. However, there are provisions in copyright law in the U.S. that are unique to the U.S., such as copyright registration. Persons in countries other than the U.S. should consult local legal counsel specializing in copyright law.
2. §1-106, Title 17, U.S. Code.
3. §1-107, Title 17, U.S. Code.
4. 37 CFR 201.26 defines public domain computer software as software which has been publicly distributed with an explicit disclaimer of copyright protection by the copyright owner. As the Free Software Foundation has stated, public domain software means software that is not copyrighted.
5. Under the Judicial Improvements Act of 1990, which authorized the creation of a national shareware registry, software copyright owners may donate their software to the public domain by assigning it to the Machine-Readable Collections Reading Room of the Library of Congress. 37 Code of Federal Regulations Part 201.26 (1991).
6. 17 U.S. Code §101.
7. 17 U.S. Code §103.
8. For an in depth discussion of the state of the law, see "Software Derivative Work: A Circuit Dependent Determination", Dan Ravicher, October 31, 2002, http://www.pbwt.com/Attorney/files/ravicher 1.pdf.
9. 17 U.S. Code §101.
10. Computer Associates Intl. VC. Altai, Inc., 982 F.2d 693 (2nd Cir. 1992).
11. Engineering Dynamics, Inc. v. Structural Software, inc., 26 F.3d 1335 (5th Cir. 1994); Kepner-Tregoe, Inc. v. Leadership Software, Inc., 12 F.3d 527 (5th Cir. 1994).
12. Gates Rubber Co. v. Bando Chem. Indust. Ltd., 9 F.3d 823 (10th Cir. 1993); Mitel, Inc. v. Iqtel, Inc., 124 F.3d 1366 (10th Cir. 1997).
13. Bateman v. Mnemonics, Inc., 79 F.3d 1532 (11th Cir. 1996); Mitek Holdings, Inc. v. Arce Engineering Co., Inc., 89 F.3d 1548.
14. Apple Computer, Inc. v. Microsoft Corp., 35 F.3d 1435 (9th Cir. 1994).
Scott's musings on life and learning (rather orthogonally) point to a somewhat mind-warping piece from 2000 by virtual reality pioneer Jaron Lanier. The content of the article was also the subject of a somewhat more substantive talk given by Lanier at Berkeley last year, in which the reliance of current computing and information theory paradigms on shared, predetermined protocols is attacked. The notion of pattern matching and spatial organization and processing of information to establish successful communication or "discover" protocols in situ is advanced.
The paper is ultra-speculative, and imho a bit unfair to the fathers of computing, but thought-provoking none the less, as are the reader responses... though Dylan Evans, once again, misses the point. I'm left wondering though, if some level of base protocol is not only desirable but unavoidable. In our world, at the lowest level (gotta be careful with statements like this, but I'll do it anyway), isn't this the laws of physics and chemistry? And we certainly use protocols (language, social protocol, etc) to navigate daily life, though clearly of a much more flexible form than current computing interfaces, and more importantly, they aren't necessary engrained but learned. Lanier's thesis might then be interpreted as the claim that "soft" methods can give rise to protocols but not vice-versa. I'm not sure I would accept that (though to be fair, I'm not sure that's what's being advanced either). Without some base level, fundamental established protocol (even if very low-level) it seems it's turtles all the way down.
Google's foes have a much firmer hold on customers, argues Seth Godin, a well-known Internet consultant and editor of last summer's widely distributed online book What Should Google Do? Competitors have troves of personal information about users that they draw on to customize products, ads, and servicesconsider the way My Yahoo brings you information on everything from your portfolio to fixing your house. They will probably use that same information to tailor search results. Google, meanwhile, knows little more about you than what you are currently searching for.
An observation made even more interesting considering that Google has an impressive arsenal of personalization technology acquired from former start-ups Kaltix and Outride.
danah's ongoing work on friendster and other social networking technologies, was just featured in a New York Times article! The reporter does a great job of introducing and framing the issues and personalities involved, including some wonderful Friendster stories and (deserved) salvos fired at friendster CEO Jonathan Abrams.
Wired reporter Leander Kahney looks into how iPod'ing familiar strangers have begun a practice of impromptu sharings of each other's music, and envisions a future of micro-radio stations, where bluetooth or wi-fi enabled iPods could wirelessly serve up tunes to their local vicinity. Definitely something I would be into...
Before the days of laptops and wi-fi, there was Stanford Research Institute's SRI van, allowing hard working geeks to go out and get trashed at south bay alcophile landmark Rossotti's whilst hacking away over packet radio... once again proving that just about all of today's modern computing paradigms were invented/developed in Palo Alto in the 1970's. (via Stu Card)
Dylan Evans recently wrote an article "Smash the Windows" (discovered via Slashdot), arguing that for computer users to be truly empowered, they must reach a much higher level of computer literacy, understanding the "insides" of the machine. Underlying this argument is a fundamental belief I share: people need to have an appropriate understanding of their tools. But even with my hyperbole filter turned up to the max, I found this article to be misguided, insulting, and fundamentally flawed. I'll start with the insulting. Consider this choice quote:
It's not just laziness, of course, that prevents people from getting to grips with computers. Cowardice also plays its part.
When someone is more concerned with being right then with helping the audience that is supposedly trapped, each "a prisoner of [their] ignorance", something is wrong. But that's not all that's wrong here.
Evans argues that computer users are largely unaware of the workings of the underlying machine, and that the graphical interface obscures the understanding of these workings. He instead advocates the use of the command line interface and the learning of programming languages as the necessary path for all users to reach "power user" status. He is right to note that many users do not understand the mechanisms at work in their computer, often preventing them from getting the most mileage out of their computer.
However, he neglects the fact that command line interfaces and programming languages are themselves carefully crafted user interfaces, an abstraction over the messy details of machine language instructions, which in turn abstract the electrical circuits we send electrons coursing through to perform computation. GUIs are just another push forward in this trend... and a incredibly powerful one at that. Human predilections for visual imagery are not something to tossed aside callously -- these skills provide ways in which to fundamentally improve human-machine communication: increasing communication bandwidth, decreasing users' cognitive burden, and often times enhancing learnability.
Consider the countless UNIX hackers who, though quite skilled with the command line interface, run the gkrellm program, providing visual monitors on system level features such as CPU utilization, memory load, and network traffic. This is a simple instance where visual representations are more intuitive and effective. To ignore this and then go on to say that computers "prefer text" is a gross mischaracterization. Programmers may prefer text because it requires less implementation and design effort. To the computer it is nothing but a series of high and low voltages coursing through silicon. This doesn't argue for an embandonment of graphical (or tactile, or auditory, etc) interfaces, it argues for continued exploration of better tools for creating such interfaces.
At the heart of Evans argument is the need for understanding how the underlying system works. I agree that this is an important part of interaction that current interfaces (both textual and graphical) obscure. To paraphrase Paul Dourish, in human-computer interaction we call this accountability: that system activity is observable and reportable, such that third parties can make sense of the activity within the context in which it arises. System activities should be observable by users on demand, and preferably in a number of fashions (system logs, charts and monitors, or more fanciful visual abstractions) so that users can interactively learn the traits of the system. Evans seems to confuse the medium through which this information is carried with the information itself.
Ideally, system design should include mechanisms for communicating that design, so that users can learn the internals of their machines through time. An interesting example would be a monitor that visually depicts the movement of data between physical and virtual memory, I suspect a simple experiment would show that an understanding of systems concepts such as thrashing would quite naturally emerge through such an interface.
In the end, I'm sympathetic to the underlying lack of user power Evans attempts to address--hell, that's why I do what I do--but I find the approach he espouses reactionary and the way in which he espouses it troubling. Introducing more programming education will undoubtedly provide the next generation with an important set of skills and conceptual structures that will facilitate success and technological competence, but let's not unduly limit the ways in which this can be expressed.
Today I was at the 2003 ACM Multimedia conference presenting a demo of the Active Capture work I've been working on for the last year with the Garage Cinema Research group at Berkeley. Active Capture is a new approach to media acquisition that combines computer vision, audition, and human-computer interaction to enable automated film direction for automatically generated movies. The conference was held here in Berkeley, so we set up an entire mini-studio in a conference room of the Berkeley Marina Mariott, including a green screen, camera, computer, etc. We had a lot of great guests participate, including some prestigious folks known for inventing some useful things. Best of all, the system more or less behaved itself, successfully capturing and rendering the vast majority of participants, automatically turning them into the stars of an MCI commercial, a Godzilla movie scene, and a trailer for Terminator 2.
For those interested, here's how it works at a high level... A participant stands in front of a green screen, where a computational unit consisting of a camera, microphone, display, and speakers directs the user through simple actions such as screaming into the camera or running in place. The system uses computer vision and audition to evaluate the performance and suggest corrections as necessary. The recorded result is then analyzed and placed into pre-existing templates to generate automatic movies. Pretty cool... and as this research progresses it should get even cooler and more useful. Applications of computer-led or computer-assisted direction include not only entertainment and media capture, but more pressing issues such as emergency evacuation services.
My particular interests are on the interesting HCI issues surrounding the mediation of human action by a computational system: how to design the directorial experience, what strategies to apply to not only guide human action, but to avoid and reduce error and misunderstanding. In the face of limited AI techniques (we use fairly simple techniques such as eye detection, motion detection, timing, and audio volume), well-designed interaction is essential to providing the necessary context fpr recognition systems as well as creating an enjoyable, engaging experience for the user.
Half HCI design and half philosophy class, Dourish's book attempts to unify recent research in tangible and social computing into a broader paradigm of "embodied interaction." Breaking with previous approaches steeped in Cartesian dualism and information processing cognitive psychology, embodied interaction is an extension of the phenomenology school of modern philosophy, as articulated by Heidegger, Merleau-Ponty, Wittgenstein, and others. It concerns engagement with the physical and social world, and recognizes that humans don't just follow set plans of action, but rather engage in a continuous improvisation in response to their surrounding contexts as they pursue goals and activities. Despite the strong philosophical slant, the book is very readable and in my opinion lays a nice foundation for both designing and interpreting interactive technologies. You won't find design guidelines or rules of thumb in this book, but you will find a useful perspective in which to frame your own analyses and ideas.
Having not read Heidegger before, I was particularly interested in the concepts of "ready-to-hand" (zuhanden) and "present-at-hand" (vorhanden) to describe our engaged status with an artifact. For example, when a skilled carpenter uses a hammer to drive a nail, the hammer is "ready-to-hand" -- the carpenter doesn't have to think about the fact that he is using a hammer, it cognitively becomes an extension of himself. That doesn't mean the carpenter can't also accidently smash his thumb, at which point he becomes keenly aware of the fact that he is wielding a hammer physically distinct from himself -- at this point the hammer becomes "present-at-hand." Apparently these concepts were introduced to the HCI community as early as 1986 by another book I need to read. Surprisingly, I haven't seen these concepts in the ubicomp literature, where they could help tease apart the oft-confused metaphors of "invisible" computing that are touted as ubicomp's ultimate goal.
The only thing I felt was noticably lacking from this book was a discussion of learning. Even embodied tasks often require some phase of learning, training, and familiarity gained through experience. I'd have loved to see an exposition of some of the features of such learning requirements as befits tangible and social computing applications. But as Dourish himself states, this book isn't intended to have all the answers. It is intended to be a beginning, to open a door into a new paradigm of interface research and development that "emphasizes the primacy of natural practice over abstract cognition." And that it most certainly does.
This video in particular got me. The first time I watched it, purposefully trying to NOT overtly look for changes, I didn't notice anything unusual. On second view, however, I saw at least 5. I still have to figure out the other 4...
I was happy to see that Apple released a windows version of iTunes -- I have been lukewarm to MusicMatch thus far and so now my iPod may have a new partner in crime. I haven't gotten around to installing it yet, but it appears I should hold off on putting it on my laptop until I upgrade to XP. As intimated to me by an audiophile friend, and corroborated by this article, the windows version doesn't always play nice with Win2k.
One of the most serious complaints came from a number of Windows 2000 Professional users, who said installing iTunes appeared to crash their machines... Patrick Nielsen Hayden, a science fiction book editor in New York, said he installed the Windows version on his PC but then was unable to use his machine. "On restart, Windows 2000 Pro got up to its "splash screen" the screen displaying the product's logo. [It] got about halfway across the progress meter ... and froze solid," he wrote in an e-mail.
Meanwhile, Microsoft has criticized the new iTunes for limiting user's available choices. Funny, that.
The second half of my northwest adventures was to attend the Ubiquitous Computing (UbiComp) conference in Seattle. It was my first time in Seattle, and it only rained one out of the three days I was there, so I made out pretty well. Took a long bus ride from SeaTac into downtown, giving me a chance to soak in some of the people and surroundings (including a large number of Seahawks fans making their way to the stadium). I stayed in downtown a few blocks from the Space Needle. For some reason the city saw fit to install a monorail from the Westlake mall in downtown to the Space Needle area... totalling a whopping half-mile of monorail action. Reminded me of a certain Simpson's episode.
The conference itself was interesting, though overall less impressive than I was expecting. Here's a run-down of some of my favorite papers:
- Very Low-Cost Sensing and Communication Using Bidirectional LEDs: this work leveraged decade old findings to use typical LEDs both as a light source and light sensor. This allowed some really cool applications, using LEDs to communicate data between devices in an extremely low cost manner.
- Inferring High-Level Behavior from Low-Level Sensors: presented a dynamic Bayesian model for inferring location and mode of transportation from GPS sensor readings.
- Finding a Place for UbiComp in the Home: some nice ethnographic work that can help guide the design and deployment of ubicomp systems in the home. That, and I am a sucker for entertaining presenters with thick Scottish accents.
- UbiTable: Impromptu Face-to-Face Collaboration on Horizontal Interactive Surfaces: An interactive table interface supporting collaborative sharing between users. Uses the very cool DiamondTouch technology presented at UIST a few years ago. This was my friend Kate's internship project.
- Social Network Computing: Discussed approaches for computers to interpret a surrounding social environment by analyzing audio feeds from a microphone.
I also think my own talk went pretty well. I was presenting a streaming query system for supporting context-aware computing, the result of a systems class project I did with my friends Alan and Chris. This was the largest crowd I've ever spoken in front of (not counting theatre or concert performances), so I couldn't resist taking a picture of the audience at the beginning of the talk. The picture captures a little over 1/3 of the room...
Overall, I enjoyed the conference, and was glad to see a mix of disciplines and approaches represented. The demonstrations as a whole leaned towards interactive art, which I appreciate, but felt that in addition there could have been some more compelling demos that tackle real-world problems. In terms of papers, I found myself getting most interested in the socially-oriented research, perhaps because I'm less familiar with it and find it more inspiring and thought-provoking than software systems design papers. That being said, in the future I'd really like to see more novel hardware contributions... the LED paper was great and I'd love to see more work on novel sensors, actuators, and input/output mechanisms.
As the years march on, I'm interested to see how these technologies we're building, discussing, and critiquing eventually influence the world around us. I'm still wondering what parts of ubicomp (e.g., context-aware computing) will catch on and what technologies or approaches won't live up to the hype. What technologies are compelling and enriching enough that end-users will clamor for them? How will they affect our privacy, our work habits, and our social lives? Already cell phones are acquiring location-tracking services, which seems like a primary vector for ubicomp work to start streaming into the market. Developments in ubicomp are already sparking plenty of skepticism and debate. For now I'm optimistic, yet vigilant. As I see it, UbiComp researchers and developers have a double burden placed upon them - not only to invent the technologies of the future that attempt to integrate computational tools into the backdrop of human activity, but to do so in a way that carefully avoids impinging upon both our liberties and humanity. Fortunately, I got the strong impression that most of my fellow conference-goers whole-heartedly share this outlook.
So Jeff and I are here in sunny Seattle blogging away at Ubicomp 2003. Talks are pretty cool, looking at various networking, systems, and interaction aspects of ubiquitous computing, systems that combine wireless networking, sensors, and devices of all form factors.
So since this is a guest blog, I won't go too much into detail about the geeky technical details, but one thing I think is really great about this conference is that it's trying to figure out not just what we could build, but what we should build.
The question, "What kind of world do we want to live in?" is more important than ever, because with these emerging technologies, we really can start molding the world according to our desires. How will these technologies affect social communities? Democracies? Education? Families? Children? Quality of life? The environment? Politics? Social justice? Art? How can we use these technologies to tackle the hard problems that face humanity?
Ok, so Jeff says I have a treatise going here, so I'll stop while I'm ahead. I'll end with one of my favorite quotes: "we may disagree about our past, but we're going to have to agree about our future together".
P.S. Jeff, your talk was awesome. I think I saw a few women swooning.
This past summer I was working and living down in Palo Alto, and through a housemate became acquainted with a little search engine start-up named Kaltix. I blogged about it back in July, and a reporter from c|net wrote an article about them. And today it was announced that Kaltix was acquired by Google. Now that Google has acquired the personalization know-how of both Kaltix and the failed start-up Outride, they are situated quite nicely for issuing in an era of personalized search. I'm eagerly awaiting their roll-out of these technologies.
And though financial terms of the deal were not disclosed, I have a feeling that the average net worth of my friends and acquaintances took quite a jump today. Congrats...
p.s. and thanks to googler.blogs.com, whose trackback ping alerted me to the acquisition.
All your escher favorites, rendered using everyone's favorite childhood toys. The links include the descriptions of how each piece was built, and what geometric or camera trickery was involved.
I love these kinds of articles, even when they are largely re-hash. This one focuses on 3-D printing, biosimulation, autonomic computing, fuel cells, and RFID tags. My quick take: 3-D printing is bad-ass, autonomic computing is in many ways overdue, I heart fuel cells, and RFID still needs to satisfactorily address privacy issues to make it into retail.
A review of Neal Stephenson's new book (part one of a trilogy named "the Baroque Cycle"), including numerous comparisons to Hofstadter's GEB. Stephenson has left his cyberpunk, nanotech, and cryptographic futures for things of the past, opting instead for a romp through the days of scientists of yore, including the Royal Society of Isaac Newton.
Our model "shows that closed-source projects are always slower to converge to a bug-free state than bazaar open-source projects," say theoretical physicists Damien Challet and Yann Le Du.
When I have some free time (yeah right), it would be nice to go back and examine their model in further depth to see if I buy their study or not.
I ran across a couple of interesting articles at wired.com in the old science meets religion department. One older article posits that science has recently become more open to religion: The New Convergence. Another article talks about the recent confluence of science and Buddhism, including fMRI studies of meditating monks: Scientists Meditate on Happiness.
For those interested in such things, I'd also recommend The Tao of Physics by Fritjof Capra, which explores parallels between modern physics and Eastern religious beliefs. The edition I read was written before quarks had reached general scientific acceptance, which does have some bearing on the author's arguments... I'd be interested to see if any newer editions react to more recent scientific developments (and unproven ideas such as string theory).
I think my favorite quote on the matter, however, comes from the judge on the Simpsons: As for science versus religion, I'm issuing a restraining order. Religion must stay 500 feet away from science at all times.
cheesebikini? has started a catalog of WiFi access points in Berkeley. It's slim pickins for the time being, especially compared to San Francisco, but good to know. Hopefully us Berkeleyites will see the list blossom a bit more in the near future...
After reading metamanda's post about personality testing, I decided I would kill a little time by taking an exam myself.
I discovered that I am apparently of type ENTJ, or "Extroverted iNtuitive Thinking Judging", with measurements of Extroverted: 1%, Intuitive: 33%, Thinking 11%, and Judging: 67%. In other words, I am very balanced with respect to my "vertedness", but make lots of judgments. I'm obviously quite suspect of the accuracy of such exams. But here I go making a judging statement... you just can't win.
More (or less, depending on how geeky you are) interestingly, I also noticed a weird effect with the font color on the page describing my personality type. It seems to involve text on a light background with hex color #660066 (that's 102,0,102 RGB for you base-10 types, or "darker magenta" for everyone else). Now either go to the page in question or check out the text below and start scrolling your web browser up and down:
The quick brown fox jumped over the lazy dogs
Do you notice the font getting brighter, more purple-y? If so, you probably are viewing on some form of LCD monitor. When I first encountered this, it weirded me out, so I tried it in a score of applications and it all worked (placing the text on a black background, however, killed the effect). I thought either I had found a cool trick of the human visual system, or a property of my display device. An unsuccessful attempt to replicate the test on a CRT monitor confirmed that the display was most likely the culprit. For reference, I'm running on an IBM Thinkpad T23, and other Thinkpad laptops have shown themselves capable of producing the effect.
A web search on the topic has not revealed anything yet, though in the process I did find that Darker Cyan (006666) seems to do the trick as well.
If you get the effect too, or better yet, know something relevant about LCD display technology, post a comment. My rough guess is that there's something about the varying response of the LCD that causes the effect to happen.
Here's the blurb: Kent Beck is known as the father of "extreme programming," a process created to help developers design and build software that effectively meets user expectations. Alan Cooper is the prime proponent of interaction design, a process with similar goals but different methodology. We brought these two visionaries together to compare philosophies, looking for points of consensusand points of irreconcilable difference.
Some excerpts:
Cooper: When you put those two constituencies together, they come up with a solution that is better than not having those two constituencies together, I grant that. But I don't believe that it is a solution for the long term; I believe that defining the behavior of software-based products and services is incredibly difficult. It has to be done from the point of view of understanding and visualizing the behavior of complex systems, not the construction of complex systems.
...So when I talk about organizational change, I'm not talking about having a more robust communication between two constituencies who are not addressing the appropriate problem. I'm talking about incorporating a new constituency that focuses exclusively on the behavioral issues. And the behavioral issues need to be addressed before construction begins.
---------------
Cooper: Building software isn't like slapping a shack together; it's more like building a 50-story office building or a giant dam.
Beck: I think it's nothing like those. If you build a skyscraper 50 stories high, you can't decide at that point, oh, we need another 50 stories and go jack it all up and put in a bigger foundation.
Cooper: That's precisely my point.
Beck: But in the software world, that's daily business.
Cooper: That's pissing money away and leaving scar tissue.
Beck: No. I'm going to be the programming fairy for you, Alan. I'm going to give you a process where programming doesn't hurt like thatwhere, in fact, it gives you information; it can make your job better, and it doesn't hurt like that. Now, is it still true that you need to do all of your work before you start?
---------------
Cooper: I'm advocating interaction design, which is much more akin to requirements planning than it is to interface design. I don't really care that much about buttons and tabs; it's not significant. And I'm perfectly happy to let programmers deal with a lot of that stuff.
----------------
Beck: The interaction designer becomes a bottleneck, because all the decision-making comes to this one central point. This creates a hierarchical communication structure, and my philosophy is more on the complex-system sidethat software development shouldn't be composed of phases. If you look at a decade of software development and a minute of software development, you ought to have a process that looks really quite similar, and XP satisfies that. And, secondly, the appropriate social structure is not a hierarchical one, but a network structure.
------------------
Cooper: Look. During the design phase, the interaction designer works closely with the customers. During the detailed design phase, the interaction designer works closely with the programmers. There's a crossover point in the beginning of the design phase where the programmers work for the designer. Then, at a certain point the leadership changes so that now the designers work for the implementers. You could call these "phases"I don'tbut it's working together. Now, the problem is, a lot of the solutions in XP are solutions to problems that don't envision the presence of interaction designcompetent interaction designin a well-formed organization. And, admittedly, there aren't a lot of competent interaction designers out there, and there are even fewer well-formed organizations.
Beck: Well, what we would call "story writing" in XPthat is, breaking a very large problem into concrete steps from the non-programming perspective still constitutes progressthat is out of scope for XP. But the balance of power between the "what-should-be-done" and the "doing" needs to maintained, and that the feedback between those should start quickly and continue at a steady and short pace, like a week or two weeks. Nothing you've said so farexcept that you haven't done it that waysuggests to me that that's contradictory to anything that you've said.
---------------------
Cooper: The problem is that interaction design accepts XP, but XP does not accept interaction design. That's what bothers me... The instant you start coding, you set a trajectory that is substantially unchangeable. If you try, you run into all sorts of problems, not the least of which is that the programmers themselves don't want to change. They don't want to have to redo all that stuff. And they're justified in not wanting to have to change. They've had their chain jerked so many times by people who don't know what they're talking about. This is one of the fundamental assumptions, I think, that underlies XPthat the requirements will be shiftingand XP is a tool for getting a grip on those shifting requirements and tracking them much more closely. Interaction design, on the other hand, is not a tool for getting a grip on shifting requirements; it is a tool for damping those shifting requirements by seeing through the inability to articulate problems and solutions on management's side, and articulating them for the developers. It's a much, much more efficient way, from a design point of view, from a business point of view, and from a development point of view.
---------------
Cooper: The interaction designers would begin a field study of the businesspeople and what they're trying to accomplish, and of the staff in the organization and what problems they're trying to solve. Then I would do a lot of field work talking to users, trying to understand what their goals are and trying to get an understanding of how would you differentiate the user community. Then, we would apply our goal-directed method to this to develop a set of user personas that we use as our creation and testing tools. Then, we would begin our transformal process of sketching out a solution of how the product would behave and what problems it would solve.
Next, we go through a period of back-and-forth, communicating what we're proposing and why, so that they can have buy-in. When they consent, we create a detailed set of blueprints for the behavior of that product.
As we get more and more detailed in the description of the behavior, we're talking to the developers to make sure they understand it and can tell us their point of view.
At a certain point, the detailed blueprints would be complete and they would be known by both sides. Then there would be a semiformal passing of the baton to the development team where they would begin construction. At this point, all the tenets of XP would go into play, with a couple of exceptions. First, while requirements always shift, the interaction design gives you a high-level solution that's of a much better quality than you would get by talking directly to customers. Second, the amount of shifting that goes on should be reduced by three or four orders of magnitude.
Beck: The process ... seems to be avoiding a problem that we've worked very hard to eliminate. The engineering practices of extreme programming are precisely there to eliminate that imbalance, to create an engineering team that can spin as fast as the interaction team. Cooperesque interaction design, I think, would be an outstanding tool to use inside the loop of development where the engineering was done according to the extreme programming practices. I can imagine the result of that would be far more powerful than setting up phases and hierarchy.
While I was an undergrad at Cal, I worked for a semester in the Robertson Visual Attention Lab with graduate student Noam Sagiv, researching synesthesia - a phenomenon in which the stimulation of one sensory modality reliably causes a perception in one or more different senses. Examples include letters and numbers having colors, sounds eliciting images (no psychedelics necessary!), and touch causing tastes.
Some of our research shed some light on what is known as the binding problem - the mismatch between our unified conscious experience of the world and the fairly well established fact that sensory processing occurs in distinct, specialized regions of the brain (e.g., a color area, a shape area, etc). I recently stumbled across this review article in which Lynn Robertson, head of the lab I had worked for, reviews these issues including some of the findings of our work. If you're into cognitive science, it's worth checking out!
Here's an article (via Salon) on the rapidly expanding web phenomenon that is friendster: Friendster is beginning to crack down on "fakesters", artificial friendster members ranging from deities to comic characters to ancient conquerers to abstract social phenomena. How would you like to have God, Homer Simpson, Beer Goggles, Charlemagne, and Conan O'Brien in your social circle? Well, not for long, according to Friendster CEO Jonathan Abrams. Enjoy the craziness while you can, and, more importantly, enjoy fee-free friend-linking while it lasts.
The article got some of my geekier sensibilities going. I'd love to get a hold of friendster's database... not only for some wonderful visualization opportunities, but also to start doing some analysis and data mining. Just imagine computing a PageRank for people and performing collaborative filtering for friends. Don't be surprised if friendster starts rolling out such advanced features in the future... though, first things first, they really need to get their systems engineering going and speed up their site. It often takes over a minute just to follow a link these days...
"It's the smallest synthetic motor that's ever been made," said Alex Zettl, professor of physics at UC Berkeley and faculty scientist at Lawrence Berkeley National Laboratory. "Nature is still a little bit ahead of us - there are biological motors that are equal or slightly smaller in size - but we are catching up."
Mobile: Self-Driving Cars - To be honest, I would trust machine drivers more than humans. RIP Fahrvegnugen?
Energy: Fuel Cells - I heart fuel cells. At least, until micro-fusion batteries are invented. Whither our hydrogen infrastructure?
Materials: Plastic Transistors - "Like OLEDs, organic transistors could be used in plastic displays within five years and in electronic paper within a decade. If scientists can make them fast enough, plastic memory and microprocessors could be next." I want to roll up my laptop and shove it in my back pocket.
Materials: OLED Displays - Within three to five years, I'll at least be able to roll up my monitor. And waste less power, too.
Broadband: Silicon Photonics - light-based, rather than electronic, traffic on silicon chips. The result? Your DSL connection will look like a 2400 baud modem in comparison.
Networking: Microsoft SPOT - Networked gadgets, obtained by hijacking existing radio frequencies. But Microsoft and Clear Channel working together? Sets off my Big Brother alarm.
Wireless: Mesh Networks - adaptive, robust, decentralized sesning and networking. Undoubtedly coming soon to a war near you.
Networking: Grid Computing - Distrubted processing a la SETI@home, only on an even grander, more general, scale. I wonder how you effectively administrate and regulate communal usage of the world's PCs?
Security: Quantum Cryptography - Want secure data transfer in the future era of quantum computing? Fight fire with fire. Now I will never know if that damn cat is dead or alive.
Components: Magnetic Memory - Mmmmmm magnetic memory (MRAM). The potential to make long boot times a thing of the past and enable faster long term storage. 10-20 years is too long to wait :(
Entertainment: Social Gaming - Very interesting... I hope that eventually designers get into augmented reality games. Otherwise our kids will never leave the house.
Software: Text Mining - Exciting technology... for those with access to the right corpus of documents. Gives me a Stephensonian vision of Google and the CIA merging. (btw, this article mentions PARC!)
Recycling: Reverse Engineering - Georgia Tech looks for ways to make computer recycling more economically attractive. But what really caught my attention was that 85% of the 63 million computers taken out of service in America ended up in landfills, where as in Europe and Japan companies are reponsible for disposing of systems appropriately. We suck.
Finally, the feature looks at current R&D at prominent research labs, including PARC, with some blurbs on Information Scent from my friend and groupmate Ed Chi. Intel | PARC | HP Labs | IBM
An article today in the New York Times discusses how more and more people (unsuprisingly in my view) are becoming technologically proficient by sheer necessity. The article includes some choice quotes from fellow PARC researchers.
SCO: Corporate Linux users must buy license. This will undoubtedly make SCO real popular with the open source community. Though their stock did rocket 11%, so there are definitely some happy folks out there. It remains to be seen how this will actually play out, but I don't like the look of it...
Apple co-founder Steve Wozniak is back with a new startup called Wheels of Zeus (wOz), offering "wireless location-monitoring technology that would use electronic tags to help people keep track of their animals, children or property." Context-aware computing pushes that much closer to everyday life.
The New York Times is running an article, and Google News has plenty for interested individuals to read.
Yahoo! makes moves to acquire Overture, fueling it's growing search engine ambitions, while Google marches on and Microsoft is making "please-put-me-in-the-game-coach" faces on the sideline. Is there a search war a-brewing? And if so what will determine the victor? Read my extended entry for random musings on search engine competition and the next evolution of search engine technology: personalized search.
Those of you who rank high on geekitude (if you need a metric, try the Geek Test - I scored 47.7%, making me an "Extreme Geek") already know that Yahoo!, still hot off its acquisition of Inktomi, is attempting to acquire Overture, who pioneered "pay-for-placement" search results and who earlier acquired AltaVista.
Strong currents are at work in the search engine world. While reigning champion and search engine super-hero Google continues it's strong march forward, Yahoo! is amassing it's own search engine super-powers. Meanwhile, in a dark cave in Redmond, Microsoft (or more precisely, the 50-member strong MSN search group) is gearing up to throw their hat into the ring. What does this mean? A showdown looms on the horizon.
But how would one hope to topple Google's page-ranking prowess? One avenue beyond leveraging the existing traffic and influence that Yahoo! and Microsoft (MSN) have would be to get the jump on the next technological advance in search technologies: personalized search.
When you enter a query at a search engine, it finds all the matching documents in the huge collections amassed by the engine's webcrawlers and then ranks them. What you see as a user are these results, presented in the order determined by this ranking. Part of Google's key to success was that its ranking mechanism, the now-famous PageRank algorithm (here's a research paper on it), exploits web hyperlink structure to identify authoritative pages on the web and rank them accordingly, creating results that you and I find much more relevant. Now imagine if such ranking mechanisms can be personalized for each and every user of the search engine. If the search engine has some knowledge of what your interests are (say, by reading in all your web bookmarks), it can tailor the result rankings to reflect those interests, resulting in search results that are that much more relevant to you.
One company has already tried this. Outride (formerly GroupFire) spun out of Xerox PARC (now PARC, Inc.) (actually, out of the very lab I work in!), with the goal of creating personalized search. Their technology was quite impressive, building off a number of PARC innovations, but they were in the right place at the wrong time. Sabotaged by the bursting dot-com bubble, and out in the market before search engine ranking performance reached the necessary threshold for robust, ubiquitous personalization, they failed to secure enough additional funding and had to shut their doors. As co-founder Jim Pitkow puts it, they were alternately "outridden" or "group-fired". Their assets (including all software and IP) were acquired by Google.
Fast forward to the present, where the clouds of search engine war may be starting to form. To achieve personalization, search engines will need to compute relevance rankings not once for the entire web (as currently done), but once per user for the entire web. Fortunately, students at Stanford'sPageRank group have recently published papers on how to speed-up PageRank computation by using some clever linear algebra (remember Stanford has also birthed Google, and actually owns a fair chunk of them). Their resulting start-up company Kaltix (web page fairly bare, as they are in stealth mode) may indeed hold the key to making commercialized personalized web search a reality, which would make Kaltix the crown jewel in any search engine giant who may acquire them. Take your bets now.
And where am I in the midst of all this? Right in the middle it seems. The founder of Inktomi was my systems class professor, Outride was spun out of my own research group, multiple former Outride employees are now good friends of mine, and incidentally, one of the Kaltix founders is currently my housemate at my subletted summer residence. I'm excited to see what happens... I'll post more as things become fit for public consumption.
I believe this originally passed through the metafilter before making it's way to me through a certain Jack Nicholson look-alike, but it's worth the redundancy:
A very vivid vision (enough annoying alliteration already) of context-aware / ubiquitous computing environments. Even though I do research in this space of technologies, I still find this pretty eerie... and it's not just due to this summer's string of the-computers-take-us-out films.



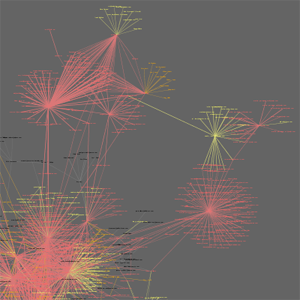
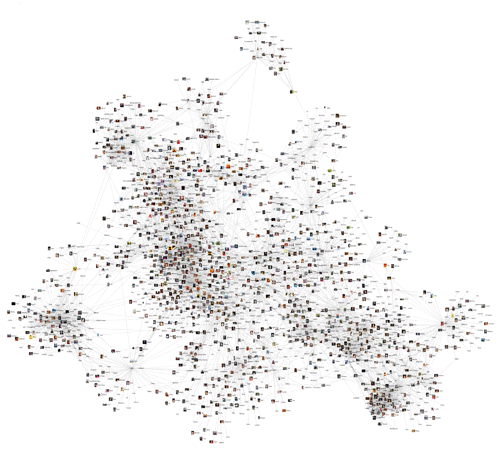



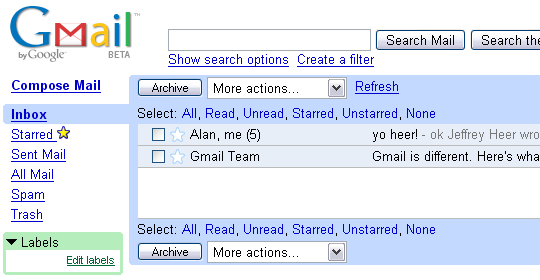

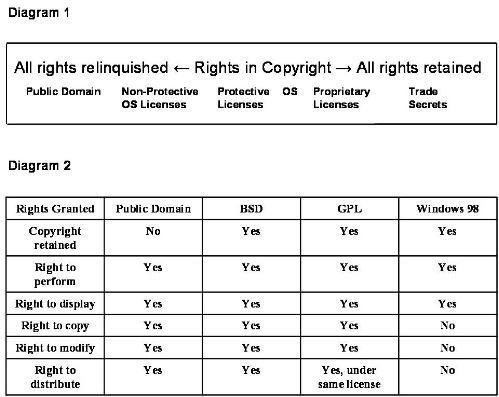


 I just finished possibly the best treatise on HCI I've read in a good long while --
I just finished possibly the best treatise on HCI I've read in a good long while -- 
